
Token là gì? Tại sao kích thước batch lại quan trọng? Và chúng ảnh hưởng đến tốc độ tính toán của AI như thế nào trên các RTX AI PC? Bài viết này sẽ giúp bạn hiểu thêm về chúng.
Kỷ nguyên PC AI đã đến với các hệ thống hỗ trợ bởi công nghệ NVIDIA RTX và GeForce RTX. Cùng với đó là một cách đánh giá hiệu suất mới cho các tác vụ được tăng tốc bằng AI, và một loạt các cụm từ mới, thông số mới có thể khiến bạn nản lòng khi lựa chọn giữa các máy tính để bàn và các laptop hiện có. Nếu game thủ đã quen với với thông số khung hình trên giây (FPS) để đánh giá hiệu năng và các thông số tương tự, thì việc đo hiệu suất AI đòi hỏi các phép đo mới.
Khởi đầu với TOPS
TOPS, viết tắt của trillions of operations per second (nghìn tỷ phép toán trên giây), là tiêu chuẩn đánh giá hiệu năng đầu tiên cho các máy tính AI. Từ quan trọng ở đây là “trillions” (nghìn tỷ) – khối lượng xử lý cần thiết cho các tác vụ AI thế hệ mới là cực kỳ khổng lồ. Hãy coi TOPS như một phép đo hiệu suất thô, tương tự như sức mạnh động cơ được tính bằng mã lực. Con số càng lớn thì hệ thống PC đó càng tốt.
Ví dụ với dòng PC Copilot+ mới được Microsoft công bố, bao gồm các bộ xử lý thần kinh (NPU) có khả năng thực hiện hơn 40 TOPS. 40 TOPS đủ để thực hiện một số tác vụ nhẹ được hỗ trợ AI, chẳng hạn như hỏi chatbot trên thiết bị về ghi chú của ngày hôm qua,…
Tuy nhiên nhiều tác vụ AI thế hệ mới sẽ đòi hỏi nhiều hơn nữa. GPU NVIDIA RTX và GeForce RTX mang lại hiệu suất chưa từng có trong tất cả các tác vụ thế hệ mới – GPU GeForce RTX 4090 cung cấp hơn 1,300 TOPS. Đây là loại sức mạnh cần thiết để xử lý các công việc liên quan đến tạo các nội dung với sự hỗ trợ AI, nâng cấp siêu phân giải bằng AI trong khi chơi game PC, tạo hình ảnh từ văn bản hoặc video, truy vấn các mô hình ngôn ngữ lớn (LLM) trên máy,…
Đưa Token vào cuộc chơi
TOPS mới chỉ là bước đầu để bạn hiểu hơn, hiệu suất của LLM trong khi đó lại được đo bằng số token mà mô hình tạo ra.
Token là kết quả của LLM, một token có thể là một từ trong một câu, hoặc thậm chí là một đoạn nhỏ hơn như dấu câu hoặc khoảng trắng. Hiệu suất cho các tác vụ được tăng tốc bằng AI có thể được đo bằng “token trên giây”.
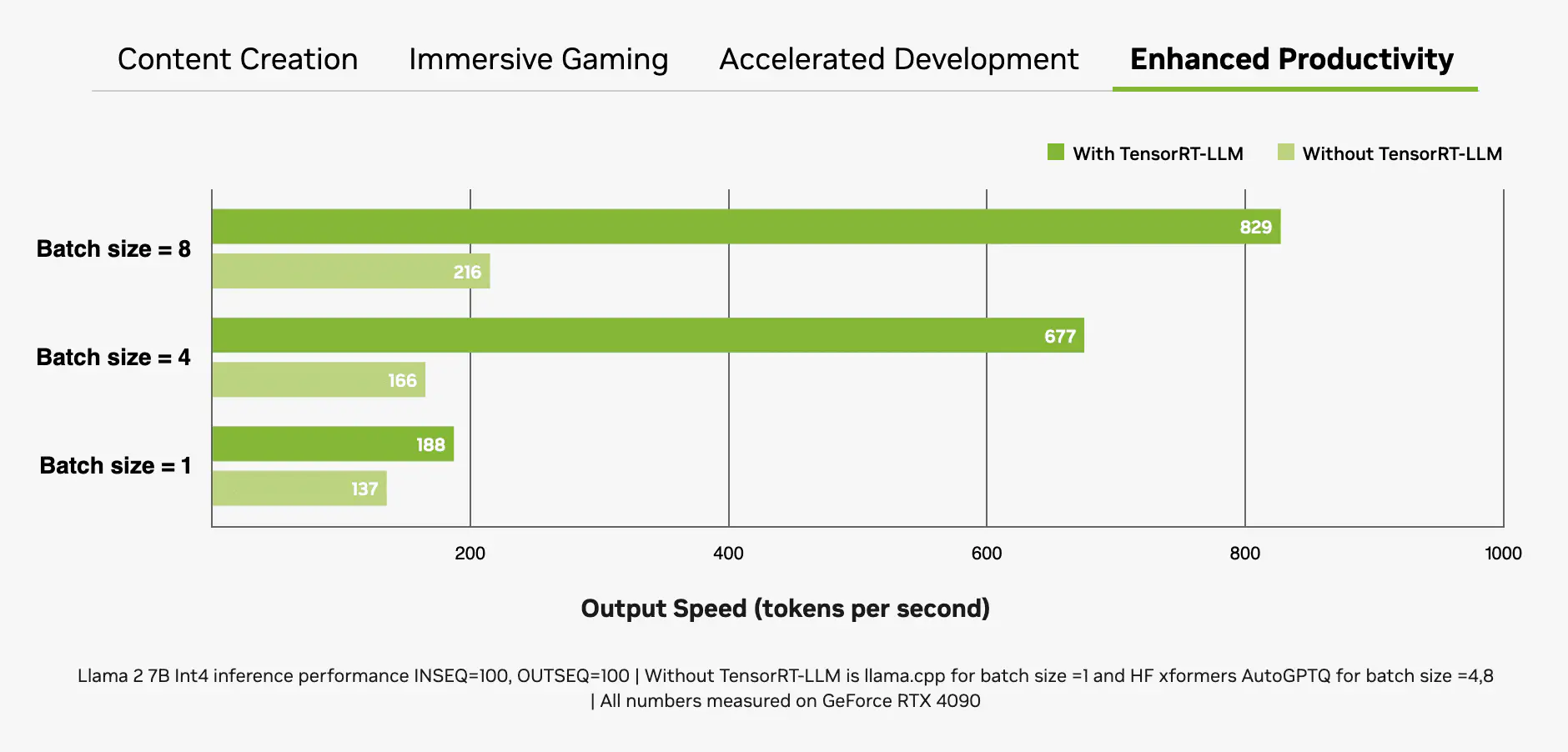
Một yếu tố quan trọng khác là kích thước batch, hay số lượng đầu vào được xử lý đồng thời trong một lần suy luận duy nhất. Vì LLM sẽ là trung tâm của nhiều hệ thống AI hiện đại, khả năng xử lý nhiều đầu vào (ví dụ: từ một ứng dụng duy nhất hoặc trên nhiều ứng dụng) sẽ là một yếu tố phân biệt chính. Mặc dù kích thước batch lớn hơn cải thiện hiệu suất cho các đầu vào, chúng đồng thời cũng yêu cầu nhiều bộ nhớ hơn, đặc biệt là khi kết hợp với các mô hình lớn hơn.
Lúc này các card đồ hoạ dòng RTX cực kỳ phù hợp với LLM do chúng có dung lượng lớn bộ nhớ truy cập ngẫu nhiên video chuyên dụng (VRAM), Tensor Core và phần mềm TensorRT-LLM. Ví dụ GPU GeForce RTX cung cấp lên đến 24GB VRAM tốc độ cao và NVIDIA RTX GPU cung cấp tới 48GB, có thể xử lý các mô hình lớn hơn và cho phép kích thước batch cao hơn. Các GPU này tận dụng lợi thế của Tensor Core – các bộ tăng tốc AI chuyên dụng giúp tăng tốc đáng kể các hoạt động tính toán chuyên sâu cần thiết cho các mô hình deep learning và AI tạo sinh.
Sự kết hợp giữa bộ nhớ, các bộ tăng tốc AI chuyên dụng và phần mềm được tối ưu hóa mang lại cho GPU RTX hiệu năng xử lý các tác vụ AI với bộ nhớ khổng lồ, đặc biệt là khi kích thước batch tăng lên.
Tạo ảnh từ văn bản nhanh hơn bao giờ hết
Để đánh giá sức mạnh của hệ thống PC AI thì việc đo tốc độ tạo ảnh từ văn bản là một cách khác để đánh giá hiệu suất. Một trong những phương pháp trực tiếp nhất sử dụng Stable Diffusion, một mô hình AI phổ biến dựa trên hình ảnh, cho phép người dùng dễ dàng chuyển đổi mô tả văn bản thành các hình ảnh phức tạp.
Với Stable Diffusion, người dùng có thể nhanh chóng tạo và tinh chỉnh hình ảnh từ các câu mô tả (prompts) trong văn bản để đạt được ảnh cho ra mong muốn. Khi sử dụng GPU RTX, những kết quả này có thể được tạo ra nhanh hơn so với việc xử lý mô hình AI trên CPU hoặc NPU.
Hiệu suất đó thậm chí còn cao hơn khi sử dụng tiện ích mở rộng TensorRT cho giao diện Automatic1111 phổ biến. Người dùng RTX có thể tạo hình ảnh từ prompts nhanh hơn tới 2 lần với điểm kiểm tra SDXL Base – giúp đơn giản hóa đáng kể quy trình làm việc với Stable Diffusion.
ComfyUI, một giao diện người dùng Stable Diffusion phổ biến khác, đã được tích hợp tính năng tăng tốc TensorRT vào tuần trước. Người dùng RTX giờ đây có thể tạo hình ảnh từ prompts nhanh hơn tới 60%, thậm chí có thể chuyển đổi các hình ảnh này thành video bằng Stable Video Diffusion nhanh hơn tới 70% với TensorRT.
Tính năng tăng tốc TensorRT có thể được kiểm tra trong tiêu chuẩn UL Procyon AI Image Generation mới, cung cấp tốc độ nhanh hơn 50% trên GPU GeForce RTX 4080 SUPER so với việc triển khai không sử dụng TensorRT nhanh nhất.
Tính năng tăng tốc TensorRT sẽ sớm được phát hành cho Stable Diffusion 3 – mô hình chuyển đổi văn bản thành ảnh được mong đợi của Stability AI – giúp tăng hiệu suất lên 50%. Thêm vào đó, công cụ TensorRT-Model Optimizer mới cho phép tăng tốc hiệu suất hơn nữa. Điều này dẫn đến tốc độ nhanh hơn 70% so với việc triển khai không sử dụng TensorRT, cùng với việc giảm 50% dung lượng bộ nhớ.
Các kết quả đã được chứng thực
Các kết quả trên đã được chứng thực. Nhóm các nhà nghiên cứu và kỹ sư AI đằng sau Jan.ai, gần đây đã tích hợp TensorRT-LLM vào ứng dụng chatbot cục bộ của họ, sau đó tự kiểm tra các tối ưu hóa này.
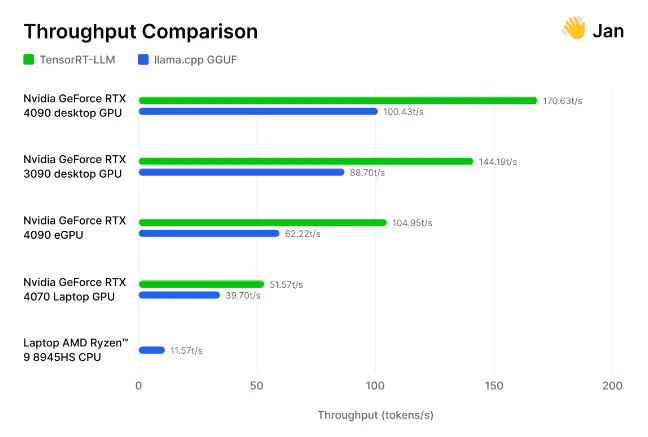
các nhà nghiên cứ đã kiểm tra việc triển khai TensorRT-LLM của họ so với engine suy luận llama.cpp mã nguồn mở trên nhiều GPU và CPU khác nhau được cộng đồng sử dụng. Họ nhận thấy rằng TensorRT “nhanh hơn llama.cpp 30-70% trên cùng phần cứng“, cũng như hiệu quả hơn trong các lần xử lý nối tiếp sau đó. Nhóm nghiên cứu cũng bao gồm phương pháp luận của mình, mời những người khác tự đo lường hiệu suất của AI tạo sinh.
Có thể thấy hiện nay từ game cho đến AI tạo sinh, tốc độ vẫn là yếu tố người dùng cân nhắc nhất. Các thông số như TOPS, hình ảnh trên giây, token trên giây và kích thước batch đều là những yếu tố cần cân nhắc khi xác định đâu là hệ thống vượt trội về hiệu suất AI hơn.


